
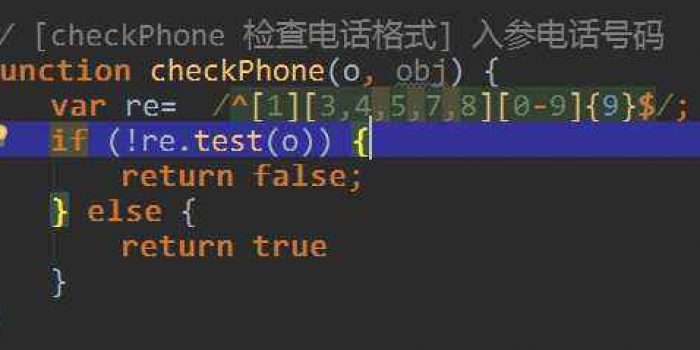
突然发现封面图片为什么不直接写 return re.test(o)???爱是可能一行代码顶ifelse之类十几行代码,恨是用不好就翻车。而且正则容易不用就忘,下文可以帮你理顺重拾,有时候倒可能还要考虑效率开销方面。在线测试可以这里尝试==>
点击右上方红色按钮关注“web秀”,让你真正秀起来
前言
作为一名程序猿,对正则表达式一定不会很陌生,但在平时开发中有时依然会遇到这样或那样的问题。本文从基础出发,本着让初学者入门,高手温故的初衷,相对系统性的介绍正了则相关知识。如有不准确的地方,欢迎吐槽
本文仅介绍 javascript 语言中的正则,其他语言虽有不同,但很类似,感兴趣的自行google吧。另外本文针对所有示例都给了输出结果,希望读者思考为什么返回这样的结果,和自己期望的有什么不一样,建议自己也动手输入一下,加深记忆。
JavaScript正则表达式详细总结
本文总体分两部分:基础知识 和 案例分析
第一部分 基础知识
一、正则申明方式
1、构造函数方式
var reg = new RegExp('\d', 'gi');
- 通过 new 构造一个正则表达式对象,其中第一个参数 ‘\d’ 是正则内容,第二个参数 ‘gi’ 是修饰符。两个参数皆为字符串类型
- 修饰符的作用是对匹配过程进行限定
- 修饰符有三种:i, g, m,可以同时出现,没有顺序(即 gi 与 ig 一样),请参考下方说明

JavaScript正则表达式详细总结
说明:
- [a-z] 表示从小写字母a到小写字母z之间的任意字符(含a和z),下文会有详细说明
- + 表示至少出现一次
- \n 在js中表示换行
- ^[a-z] 表示以任意小写字母开头的行
'aBcd efg'.match(/[a-z]+/); // ["a"] 'aBcd efg'.match(/[a-z]+/i); // ["aBcd"] 'aBcd efg'.match(/[a-z]+/g); // ["a", "cd", "efg"] 'aBcd efg'.match(/[a-z]+/gi); // ["aBcd", "efg"] 'aB\ncd\n efg'.match(/^[a-z]+/m); // ["a"] 'aB\ncd\n efg'.match(/^[a-z]+/g); // ["a"] 'aB\ncd\n efg'.match(/^[a-z]+/gm); // ["a", "cd"] // 注意不是 ["a", "cd", "efg"]
具体用法请看下文相关的示例
2、字面量方式
相比较上一种方式,这一种更为常见,上面示例也都使用了这种方式
var reg = /\d/gi;
两个斜线内为正则的内容,后面可以跟修饰符,与第一种构造函数方式相比更简洁,缺点是正则内容不能拼接,对于大多数场景俩说足够了
二、正则相关符号
1、方括号 [] 用法
用于查找方括号内的任意字符:
JavaScript正则表达式详细总结
注意:
1)^ 在 [] 内开始位置及正则双斜线开始位置有特殊含义,其他位置表示 ^ 字符本身
- // 正则开头位置表示以某某开头的字符串,如下表示以大写或小写字母开头的且连续为字母的字符串:
'adobe 2016'.match(/^[a-zA-Z]+/); // ["adobe"]
- 在正则 或 匹配中(即 | 匹配),表示 或者以某某字符开始的字符串,如下表示匹配 连续数字 或 以小写字母开头且连续为小写字母的字符串,所以返回结果包含2016 和 adobe,注意返回结果不是 [“2016”, “adobe”]
'adobe2016ps'.match(/\d+|^[a-z]+/g); // ["adobe", "2016"]
- 在 [] 内开始位置时,表示不匹配 [] 内除 ^ 以外的所有字符:
'adobe'.match(/[^abc]/g); // ["d", "o", "e"]
注: $ 与 ^ 的前两个用法相似,只不过匹配的是以某某字符结尾的字符串,举例:
'adobe 2016'.match(/\d+|[a-z]+$/g); // ["2016"] 'adobe'.match(/\d+|[a-z]+$/g); // ["adobe"]
2)- (连字符)表示左边字符的 ASCII 值到右边字符 ASCII 编码值之间及左右字符自身的所有字符
'adobe PS 2016'.match(/[a-g]/g); // ["a", "d", "b", "e"]
3)- 连字符左侧的字符对应的 ASCII 值一定要小于或等于右侧的字符,否则会报语法错误
'adobe'.match(/[z-a]/); // Uncaught SyntaxError: Invalid regular expression: /[z-a]/: Range out of order in character class...
4)如果希望对连字符 – 本身进行匹配,需要用反斜线转义
'adobe-2016'.match(/[a-g\-]/g); // ["a", "d", "b", "e", "-"]
5)查看 ASCII 表就会发现,大写字母的 ASCII 值是小于小写字母的,因此下面用法会报语法错误
'adobe-2016'.match(/[a-Z]/g); // Uncaught SyntaxError: Invalid regular expression: /[a-Z]/: Range out of order in character ...
那么问题来了,如果要表示所有字母,不区分大小写怎么办呢?其实有两种方式:
A、第一种是使用修饰符 i,前面提到过。举例:
'adobe-PS'.match(/[a-z]/gi); // ["a", "d", "o", "b", "e", "P", "S"]
B、第二种是在正则中明确指明大小写字母,举例:
'adobe-PS'.match(/[a-zA-Z]/g); // ["a", "d", "o", "b", "e", "P", "S"]
返回结果跟第一种一样。当然这个例子有些特殊:匹配了所有大小写字母。当只匹配部分大小写字母的时候只能使用第二种方式,在此就不做示例了,读者可以自己测试
6)匹配大小字母不能写成 [A-z],虽然不会报语法错误,但隐式的放大了匹配范围,查看 ASCII 会发现,在大写字母 Z 到小写字母 a 之间还有 [、 \、 ]、 ^、 _、 ` 这6个字符,因此不能这么写。
7)想必有同学会问, \w 不也可以匹配字母么?是的,\w 确实可以匹配字母,但跟上面说的一样,也隐式的放大了匹配范围,\w 除了匹配大小字母外还匹配了数字和下划线,即 \w 与 [A-Za-z0-9_] 等价,当然 A-Z、a-z、0-9(等价于\d)、_这四组没顺序之分
2、特殊含义字符
- . 匹配任意单个字符,除换行和结束符
'1+0.2*2=1.4'.match(/.{2}/g);
// ["1+", "0.", "2*", "2=", "1."]
- \w 匹配任意单词字符(数字、字母、下划线),等价于[A-Za-z0-9_]
'ad34~!@$ps'.match(/\w/g); // ["a", "d", "3", "4", "p", "s"]
- \W 匹配任意单词字符,与\w相反,等价于[^A-Za-z0-9_]
'ad34~!@$ps'.match(/\W/g); // ["~", "!", "@", "$"]
- \d 匹配数字,等价于 [0-9]
'ps6'.match(/\d/g); // ["6"]
- \D 匹配非数字,等价于 [0-9]
'ps6'.match(/\D/g); // ["p", "s"]
- \s 匹配空白字符,主要有(\n、\f、\r、\t、\v),注意’a\sb’中的\s依然是字符s,所以’a\sb’.match(/\s/g)返回 null
'adobe ps'.match(/\s/g); // [" "]
- \S 匹配非空白字符,与\s相反
'adobe ps'.match(/\S/g); // ["a", "d", "o", "b", "e", "p", "s"]
- \b 匹配单词边界,注意连续的数字、字母或下划线组成的字符串会认为一个单词
'adobe(2016) ps6.4'.match(/\b(\w+)/g); // ["adobe", "2016", "ps6", "4"]
- \B 匹配非单词边界,仔细体会下面的示例与\b的结果
'adobe(2016) ps6.4'.match(/\B(\w+)/g); // ["dobe", "016", "s6"]
- \0 匹配NUL字符
'\0'.match(/\0/); // ["NUL"]
- \n 匹配换行符(编码:10,newline)
'adobe\nps'.match(/\n/).index; // 5
- \f 匹配换页符
'adobe\fps'.match(/\f/).index; // 5
- \r 匹配回车符(编码:13,return)
'adobe\rps'.match(/\r/).index; // 5
- \t 匹配制表符,键盘tab对应的字符
'adobe\tps'.match(/\t/).index; // 5
- \v 匹配垂直制表符
'adobe\vps'.match(/\v/).index; // 5
- \xxx 匹配以八进制数xxx规定的字符
'a'.charCodeAt(0).toString(8); // "141" 'adobe ps'.match(/\141/g); // ["a"]
- \xdd 匹配以十六进制数dd规定的字符
'a'.charCodeAt(0).toString(16); // "61" 'adobe ps'.match(/\x61/g); // ["a"]
- \uxxxx 匹配以十六进制数xxxx规定的 Unicode字符,注意位数不够需要补0
'a'.charCodeAt(0).toString(16); // "61" 'adobe ps'.match(/\u0061/g); // ["a"]
注意:
window系统回车换行符为\r\n,linux系统下没有\r,linux系统通过vi编辑器打开window系统的文本文件时候,经常在行尾出现^M符号,也就是\r的原因,解析文本的时候需要注意相关判断。
3、量词说明
- n+ 匹配包含至少一个n的字符串
'adobe paas'.match(/a+\w+/g); // ["adobe", "aas"]
- n* 匹配包含零个或多个n的字符串
'ab3 aa12bb'.match(/a*\d+/g); // ["3", "aa12"]
- n? 匹配包含零个或一个n的字符串
'ab3 aa12bb'.match(/a?\d+/g); // ["3", "a12"]
- n{x} 匹配包含连续x个n的字符串
'ab3 aa12bb aaa34'.match(/a{2}\d+/g);
// ["aa12", "aa34"]
- n{x,y} 匹配包含至少连续x个且最多连续y个n的字符串
'a3 aaa12bb aaaaaaa34'.match(/a{2,4}\d+/g);
// ["aaa12", "aaaa34"]
- n{x,} 匹配包含至少连续x个n的字符串
'a3 aaa12bbaa4'.match(/a{2,}\d+/g);
// ["aaa12", "aa4"]
由上可知,以下 表达式1 与 表达式2 等价
JavaScript正则表达式详细总结
4、符号说明
符号 {}、^、$、*、+、?、[]、[^]、- 已经在前面介绍过,接下来看下其他特殊字符
- a|b 匹配包含a或b的字符串
'adobe ps13'.match(/([a-g]+l\d+)/g); // ["ad", "be", "13"]
- / 字面量方式申明正则时的界定符
'adobe'.match(/\w+/); // ["adobe"]
- \ 普通反斜线字符
'a\\dobe'.match(/\\/); // ["\"]
5、小括号 () 用法
正则在非全局(g)模式下,通过match方式,返回的数组第一个值整体匹配的字符串,其他值为通过括号分组匹配到的
1)捕获用法
- 表示对匹配的字符串进行分组
'adobe cs9cs10, adobe cs11'.match(/([a-z]+\d+)+/);
// ["cs9cs10", "cs10"]
// 注意{2,}是对 括弧内的匹配 的描述
- 与|一起使用表示选择性
"he is 12. she is 13. it's box".match(/(it|she|he)\s+is/g); // ["he is", "she is"]
- 表示对匹配的字符串捕获
'adobe cs9'.match(/[a-z]+\d+/); // ["cs9"] 'adobe cs9'.match(/[a-z]+(\d+)/); // ["cs9", "9"]
- 表示对匹配的字符串反向引用,引用从 \1 开始,从正则左侧第一个左括号(当然要是闭合的括号才行)开始计算,每多一对括号,引用数加一,在非捕获情况下不会加一。但正则比较复杂时,减少引用可以提升匹配性能,关于 非捕获 下方会详细介绍
引用的结果可以通过 构造函数 RegExp 获取,即 RegExp.$1一直到 RegExp.$9
'Can you can a can as a canner can can a can?'.match(/([cC]an+)\s+\1/g); // ["can can"] // 注意 `\1` 等价于正则里的 `([a-z]+)`,即与下面示例相同 'Can you can a can as a canner can can a can?'.match(/[cC]an+\s+[cC]an+/g); // ["can can"] // 如果把括弧去掉可以看下结果 'Can you can a can as a canner can can a can?'.match(/[cC]an+\s+\1/g); // null
2)非捕获用法,以(?)形式出现
- (?:n ) 表示非捕获组
// 不使用括号时 'adobe12ps15test'.match(/[a-z]+\d+[a-z]+/); // ["adobe12ps"] // 使用括号分组 'adobe12ps15test'.match(/[a-z]+(\d+)([a-z]+)/); // ["adobe12ps", "12", "ps"] 'adobe12ps15test'.match(/[a-z]+(?:\d+)([a-z]+)/); // ["adobe12ps", "ps"] // 看起来上面语句不用(?:)也可以得到相同结果,即: 'adobe12ps15test'.match(/[a-z]+\d+([a-z]+)/); // ["adobe12ps", "ps"] // 注意,但需求希望匹配字母之间的规则复杂时,如希望匹配字母,且字母之间可以为1或3时,但不需要1和3 'adobe11ps15test'.match(/[a-z]+(1|3)+([a-z]+)/); // ["adobe11ps", "1", "ps"] // 返回中不希望包含数字怎么办,可以使用非捕获 'adobe11ps15test'.match(/[a-z]+(?:1|3)+([a-z]+)/); // ["adobe11ps", "ps"]
- (?=n ) 匹配任何其后紧跟字符n的字符串,但返回中不包含n
'adobe12ps15test'.match(/[a-z]+(?=\d)/g); // ["adobe", "ps"]
- (?!n ) 匹配任何其后没有紧跟字符n的字符串,返回中不包含n
'adobe12ps15test'.match(/[a-z]+(?!\d)/g); // ["adob", "p", "test"]
- (?<=n ) 匹配任何其前紧跟字符n的字符串,返回中不包含n
'adobe12ps15test'.match(/(?<=\d)[a-z]+/g); // ["ps", "test"]
- (?<!n ) 匹配任何其前紧跟字符n的字符串,返回中不包含n
'adobe12ps15test'.match(/(?<!\d)[a-z]+/g); // ["adobe", "s", "est"]
3)注意
- A、如果希望对上面特殊字符本身进行匹配,需要在其前面添加\进行转移
'11+2=13'.match(/\d+\+/g); // ["11+"] '(11+2)*2=26'.match(/\(\d+\+\d+\)/g); // ["(11+2)"]
- B、\\举例
// 注意下面两个表达式返回的结果 'path C:\Windows\System32'.match(/([a-zA-Z]:\\\w+)/g); // null 'path C:\\Windows\\System32'.match(/([a-zA-Z]:\\\w+)/g); // ["C:\Windows"]
说明:
在申明字符串 ‘path C:\Windows\System32’ 时,其中的 ” 就已经被当做转移符,既是 ‘\W’ === ‘W’,所以如果希望申明的字符串中包含反斜线,需要在加一个反斜线转义,即 \\
6、正则相关方法
1) RegExp对象相关方法
JavaScript正则表达式详细总结
2)String对象相关方法
JavaScript正则表达式详细总结
3)replace 具体用法
顾名思义,是字符串替换方法,但用法比较广泛,相信读者已经非常熟悉了。在此就当复习了
A、 基本用法
直接传入字符串进行替换,找到子串后只替换一次,举例:
'adobe abc'.replace('b', '_')
// "ado_e abc"
// 注意 第二个 b 没有被替换
如果希望全部替换,可以使用正则表达式并用全局修饰符 g 方式,举例:
'adobe abc'.replace(/b/g, '_') // "ado_e a_c"
B、 高级用法
第二个参数可以使用 function,其中有三个参数,分别为 匹配的字符串、当前匹配的字符串index值、匹配的源字符串,最终结果根据每次匹配结果进行相应的替换
举例:
'adobe aacc bbaa'.replace(/a+/g, function(str, index, source){
if(index > 0){
return str.toUpperCase();
} else {
return str;
}
});
// "adobe AAcc bbAA"
第二部分 案例分析
一、常见匹配
在写正则之前,需要注意以下几点:
- 一定要清楚期望的规则是什么,不然无从匹配
- 有些正则不只一种写法,要注意简短干练,复杂的正则表达式不仅难懂,而且容易出BUG,性能也不是很好
- 正则虽好,可要适度奥。有些字符串处理不一定适合用正则
1、手机号
规则:以1开头第二位为3、5、7、8且长度为11位的数字组合
/^1[3578]\d{9}$/.test(13600001111);
// true
2、 字符串提取
举例:提取字符串中的数字
分析:
根据对数字的理解,可能为负数,即-?,如果是负数,其后需要是数字且至少一位,即 -?\d+,小数部分可能有也可能没有,所以需要对小数部分括弧起来用 ? 或 {0, 1}限定,因为.是特殊字符需要转义,于是表达式为:-?\d+(\.\d+)?
'(12.3 - 32.3)*2 = -40'.match(/-?\d+(\.\d+)?/g); // ["12.3", "32.3", "2", "-40"]
二、jQuery中的正则片段
1、表达式
在jQuery 3.1.2-pre中找到一个解析单标签的正则,如下:
/^<([a-z][^\/\0>:\x20\t\r\n\f]*)[\x20\t\r\n\f]*\/?>(?:<\/\1>|)$/i
2、分解
乍一看有点懵,其实拆解之后就容易理解了,注意拆解的步骤,通常来说:
1) 第一步可以先看括号 () ,可以将各个小括号及非括号的分成不同部分,如
/^< ([a-z][^\/\0>:\x20\t\r\n\f]*) [\x20\t\r\n\f]*\/?> (?:<\/\1>|) $/i
2) 第二步可以将中括号分开
/^< ( [a-z] [^\/\0>:\x20\t\r\n\f]* ) [\x20\t\r\n\f]* \/?> (?:<\/\1>|) $/i
现在是不是已经很清楚了,接下来分解下,就很容易理解了
3、详解
- 1)^< 很明显在匹配标签左尖括号括号,且以其开始
- 2)( [a-z] [^\/\0>:\x20\t\r\n\f]* ) 这个括号有两部分,第一个 [a-z] 没什么好解释,即标签<紧跟的必须为字母,因为全局加了 i(忽略大小写) 修饰符,所以大小写字母都可以;[^\/\0>:\x20\t\r\n\f]*,及限制标签名必须以字母开始,且第二个字母不能为/ \0 > : \20 t\r \n \f的任意多个字符(思考为什么),() 表示对标签的分组,方便取到标签名
- 3)[\x20\t\r\n\f]* 表示可能含有 [\x20\t\r\n\f] 这些特殊字符,与前面的 [^\/\0>:\x20\t\r\n\f]* 相似却不一样,通过这里可以看出<br之后进行回车也能匹配到
- 4)\/?> 能匹配 <br>或<br/>
- 5)(?:<\/\1>|) 这里不捕获,并用\1去反向引用第一个括号的表达式 ([a-z][^\/\0>:\x20\t\r\n\f]*)。这里的|表示 <\/\1> 可有可无,即:(?:<\/\1>|) 与 (?:<\/\1>)?匹配结果一样
公告
喜欢小编的点击关注,了解更多知识!
万一还有不清楚的,可以查看mozilla的官网介绍==>